Le brief
Une agence de recrutement fictive basée à New York envoie de la prospection à froid à des hiring managers à propos de leurs postes d'ingénierie ouverts, en affirmant avoir un candidat qui matche les critères. La description du candidat est volontairement générique mais suffisamment crédible pour générer de l'intérêt. Une fois que le prospect répond et signe, l'agence lance la vraie recherche candidat.
Le système doit gérer le pipeline complet : trouver les job postings pertinents, qualifier les entreprises, identifier les bons décideurs, enrichir leurs coordonnées, générer des emails qui référencent le poste spécifique, et exporter vers un Google Sheet (revue client) plus Smartlead (exécution). La conservation des crédits est centrale, le pipeline doit pouvoir scaler sans cramer le budget enrichissement sur des données mauvaises.
Architecture
Cinq tables Clay interconnectées, chacune avec un rôle précis. Les tables 3, 4 et 5 sont des caches qui stockent les enrichissements précédents pour qu'une re-run ne paie jamais deux fois la même donnée.
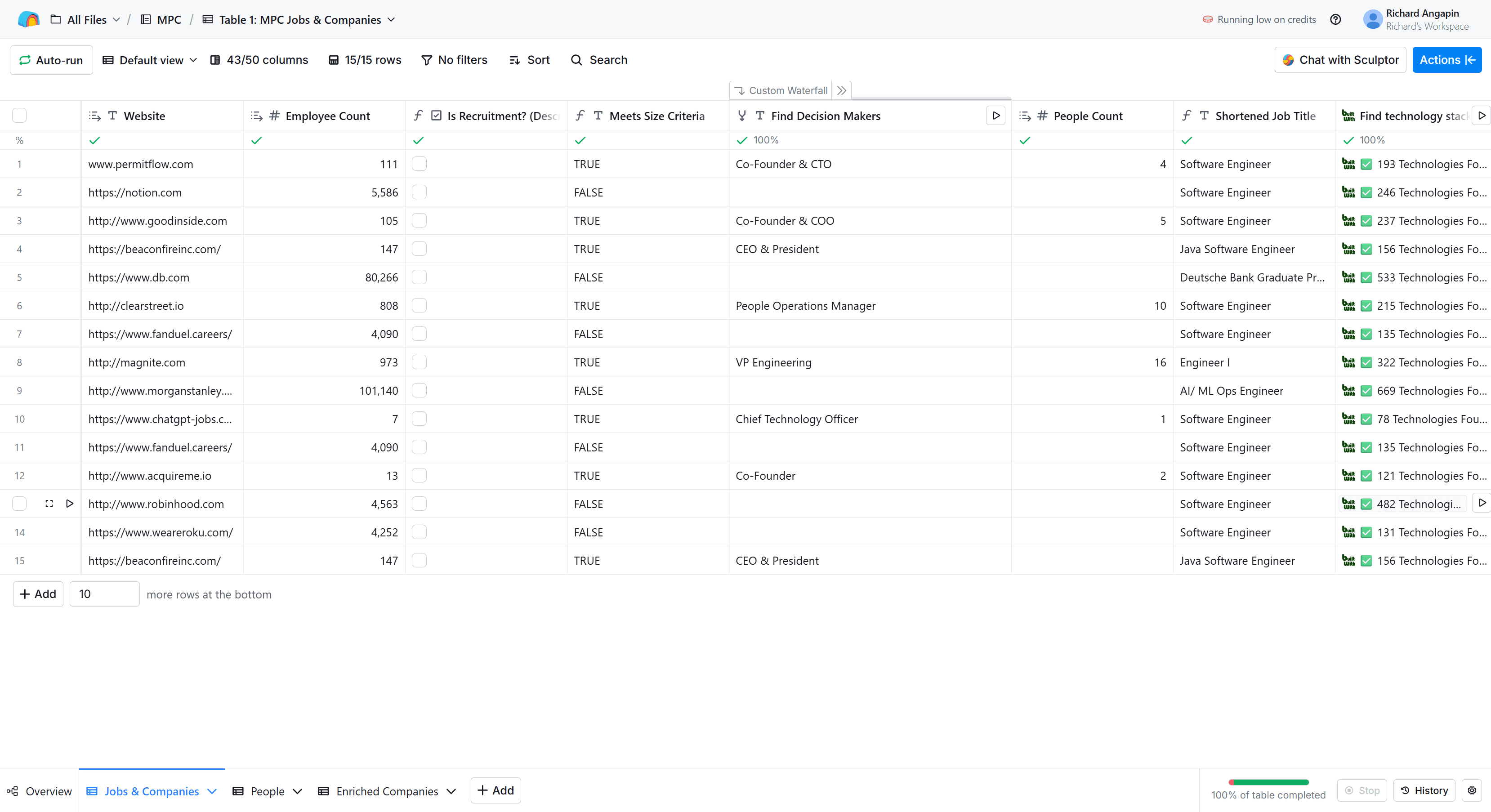
- Table 1 — Jobs & Companies. Ingère les job postings, qualifie les entreprises, enrichit les données entreprise, trouve les décideurs, extrait les variables email du job posting.
- Table 2 — People. Reçoit les contacts depuis Table 1, enrichissement email et téléphone via waterfall, génération de l'email personnalisé, export vers Google Sheets et Smartlead.
- Table 3 — Enriched Companies (cache). Indexée sur l'URL entreprise. Table 1 saute l'enrichissement quand une entreprise a déjà été traitée.
- Table 4 — Cleaned Job Titles (cache). Stocke les job titles raccourcis pour que la formule IA ne re-traite pas un titre déjà nettoyé.
- Table 5 — Enriched People (cache). Indexée sur URL LinkedIn. Table 2 saute l'enrichissement quand un contact a déjà été enrichi sur un run précédent.
Qualification entreprise
Le premier filtre est un check « est-ce une agence de recrutement ? ». Avant tout enrichissement payant, une formule IA classifie l'entreprise sur la seule base de son nom :
You are classifying companies as recruitment/staffing firms or not.
Company name: {{companyName}}
A recruitment/staffing company is one whose primary business is placing
candidates at other companies. This includes staffing agencies, talent
acquisition firms, headhunters, employment agencies, and HR outsourcing
firms that focus on hiring.
It does NOT include:
- Software companies that happen to make HR/recruiting tools
- Consulting firms that do strategy or tech work
- Companies with "talent" or "people" in their name that are not
staffing firms
Based ONLY on the company name, is this most likely a recruitment or
staffing company?
Return ONLY: TRUE or FALSELe prompt est volontairement étroit. Il n'utilise que le nom, pas la description ni le site, parce que ce check tourne avant tout enrichissement. Les règles d'exclusion sont essentielles. Sans elles, des entreprises comme Greenhouse (ATS) ou BambooHR (plateforme RH) seraient marquées agence de recrutement et n'atteindraient jamais le pipeline.
Pour les entreprises qui passent, l'enrichissement Clay tire le domaine, le nombre d'employés, le secteur. Une formule vérifie ensuite que le headcount est sous 1 000 employés. Au-dessus, l'entreprise est filtrée puisque l'agence cible des organisations plus petites où le décideur est plus accessible. Notion (5 586 employés), Deutsche Bank (80 266), Morgan Stanley (101 140), FanDuel (4 090), Robinhood (4 563) et Roku (4 252) ont été correctement filtrés. Sont passés : PermitFlow, Good Inside, Clear Street, Acquire Me, ChatGPT Jobs, Magnite.
Découverte des décideurs adaptée à la taille
Pour les entreprises qualifiées, un waterfall custom de 5 providers cherche les décideurs. La logique de ciblage s'adapte à la taille :
- Plus de 400 employés : VP Engineering, Director of Engineering, et leadership technique senior similaire.
- 400 employés ou moins : CEO, Founder, Co-Founder, CTO, VP/Director Engineering, plus titres RH.
La distinction compte parce que dans une plus petite entreprise, la décision de recrutement appartient souvent au fondateur ou au CTO, alors que les plus grandes ont du leadership engineering dédié qui gère le recrutement.
Variables email extraites du job posting
Une fois l'entreprise qualifiée, plusieurs colonnes IA extraient les variables nécessaires à l'email. Chaque prompt est pensé pour produire une sortie propre qui s'insère dans le template sans édition manuelle.
Job title raccourci
Une formule IA strip les niveaux de séniorité, qualifiers et bruit des titres LinkedIn bruts. Avec un wrapper conditionnel qui vérifie le cache avant de tirer la formule, l'IA ne se déclenche que sur cache miss. « Engineer I, Applied LLM Team » devient « Software Engineer ». « Senior Full Stack Software Engineer » devient « Full Stack Engineer ».
Niche entreprise
La variable « industrie similaire » dans l'email. Le prompt pousse vers la spécificité plutôt qu'accepter des labels génériques. Sans exemples le LLM revient sur « technology » ou « software platform ». Avec exemples : « construction compliance » (PermitFlow), « parenting empowerment » (Good Inside), « capital markets platform » (Clear Street).
Key responsibility
Génère une phrase d'achievement au passé qui se lit naturellement comme la description d'un candidat dans l'email. La sortie doit rester suffisamment vague pour décrire un candidat fictif (puisque l'agence n'a pas réellement quelqu'un en main) mais suffisamment spécifique au domaine pour rester crédible. Le format « Has... » force l'IA dans le langage achievement plutôt que la description de poste.
Cache à trois niveaux
Trois tables cache éliminent l'enrichissement redondant.
- Cache entreprise. Indexé sur URL. Si PermitFlow apparaît dans le scrape de janvier puis revient en février avec un nouveau job, l'enrichissement entreprise est entièrement skipé. Le domaine, headcount, secteur et description cachés sont récupérés gratuitement.
- Cache job title. Indexé sur la string brute. « Software Engineer » n'a besoin d'être nettoyé qu'une fois. Toute ligne suivante avec le même titre tire du cache au lieu de relancer la formule IA.
- Cache people. Indexé sur URL LinkedIn. Si un VP Engineering a été trouvé et enrichi pour un job posting, et que la même entreprise poste un autre rôle le mois suivant, ses email et téléphone sont tirés du cache.
Au-delà du caching, les gates de qualification empêchent la perte de crédits à chaque étape. Le check agence de recrutement tourne avant toute enrichissement payant. Le filtre headcount tourne avant la découverte des décideurs, l'extraction du tech stack, et toute la génération de variables IA.
Workaround Smartlead
Une découverte pendant le setup : les custom fields Smartlead importés via CSV ne sont pas accessibles comme variables dans l'email. Seuls les 7 built-ins fonctionnent (First Name, Last Name, Email, Phone Number, Company Name, Website, LinkedIn Profile, Location). Le workaround consiste à générer l'email body complet dans Clay et le passer comme un single custom field, ce que Smartlead accepte comme variable.
Pour empêcher d'envoyer au même contact dans une fenêtre 30 jours, un workflow n8n agit comme rate limiter entre Clay et Smartlead. Avant qu'un contact soit poussé vers Smartlead, n8n vérifie si cet email a été contacté dans les 30 derniers jours. Si oui, l'envoi est bloqué.
Résultats
Au départ : 15 job postings scrapés depuis LinkedIn.
- 15 entreprises ingérées, agences de recrutement et > 1 000 employés filtrées
- 83 décideurs trouvés sur les entreprises qualifiées
- Enrichissement email et téléphone complété pour les 83 contacts
- Les 3 tables cache opérationnelles
- Campagne Smartlead configurée avec le workaround email body
Stack
- Clay — plateforme principale (tables, waterfalls, formules IA, cache)
- Apify (bebity/linkedin-jobs-scraper) — scrape LinkedIn jobs
- Smartlead — exécution campagne et séquençage
- n8n — logique anti-réenvoi entre Clay et Smartlead
- Google Sheets — revue client, export CSV